



Lorsque nous sommes rentrés en comité de rédaction et que le sujet des spider traps a été proposé, certains ont dit « c’est so 2015 comme sujet » ! Et pourtant, dans les 12 derniers mois, plusieurs consultants Search Foresight ont été confrontés à ce problème SEO. L’idée ici, est de comprendre ce qui a été bien ou mal mis en place et de faire la chasse aux idées et méthodes qui, de prime abord, vous semblent pertinentes, mais qui de toute évidence ne fonctionnent pas.
Envie de gagner du temps ?
Faites résumer cet article par l’IA en quelques secondes.
Spider Trap : définition
Un spider trap (piège à robots dans la langue de Molière) est un disfonctionnement du maillage interne d’un site web qui va générer une suite infinie de liens. Les spiders ou robots d’exploration comme Google Bot, Bing bot se servent des liens internes pour découvrir les pages d’un site web, les crawler et les indexer. Ce crawl a un début et une fin. Or un spider trap empêche que l’exploration d’un site web ne se termine, car les robots s’engouffrent dans le piège.
Si vous utilisez un crawler SEO, comme Botify ou Screaming Frog, et qu’un crawl est anormalement long et bloque une fois la barre des 99% atteinte, vous pouvez alors stopper le crawl et regarder ce qu’il se passe. Pour Google, c’est différent. Il n’a pas le temps, car il doit crawler d’autres sites, beaucoup d’autres sites ! Un autre inconvénient est que pendant qu’il explore ces URLs, en général peu qualitatives, il loupe probablement votre super dernier contenu optimisé.
La plupart du temps, c’est du moins ce que nous observons chez Search Foresight, le spider trap provient :
- d’une navigation à facettes accessible au crawl (en HTML) créant des milliers de combinaison possibles ;
- de la pagination sur ces URLs de facettes indexables ;
- d’une mauvaise gestion du moteur de recherche interne créant une nouvelle URL à chaque recherche en créant un lien hypertexte HTML ;
- de la création d’URL à paramètres à chaque nouvelle session.
Si le spider trap est détecté suffisamment tôt, c’est gérable ! On change de techno et c’est réglé ! Si en revanche il est actif sur un domaine depuis plusieurs mois ou plusieurs années, vous pouvez vous retrouver avec des milliers d’URLs dupliquées et indexées.
Cela pose notamment les problèmes suivants :
- dilution du page rank interne ;
- duplication ou quasi-duplication d’URL ;
- génération de pages vides ;
- gaspillage de budget de crawl (uniquement valable pour les très gros sites à plusieurs centaines de milliers ou millions de pages).
S’en suis alors un long chemin de pénitence pour désindexer toutes vos URLs et cela peut prendre longtemps, voire très longtemps ! Vous devrez ensuite gérer les (très probables) impacts SEO comme la baisse de nombre de mots clés positionnés, une baisse du trafic SEO, et quel mauvais signal envoyé aux moteurs de recherche !
Ok, nous sommes peut-être un peu durs avec les robots, car des les faits Google s’engouffre beaucoup moins qu’avant dans ce type de piège et les impacts sont à présent modérés.
Éviter un Spider Trap : les fausses bonnes idées
Nous avons été et sommes encore confrontés à des méthodes « old school » misent en place il y a quelques années en pensant bien faire, mais qui de toute évidence montrent tôt ou tard leurs limites, où sont voir même tout à fait inefficaces !
Gérer les facettes avec le robots.txt
C’est une très, très mauvaise idée pour les raisons suivantes :
- cela n’empêche pas l’indexation (le rapport « URLs indexées malgré le blocage au robots.txt » de la Google Search Console en est la preuve) ;
- cela n’aura pas d’incidence sur la dilution de la popularité interne ;
- c’est souvent source d’erreur humaine et donc de problème par la suite, en créant par exemple des règles qui vont se contredire et donc rendre une directive inefficace !
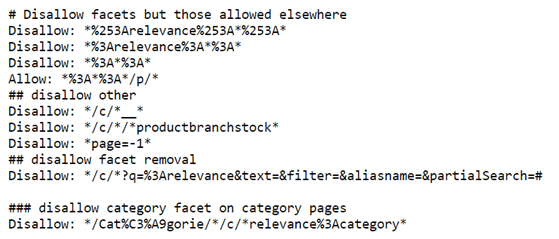
Le robots.txt (et Google nous le redit) doit être utilisé pour bloquer l’exploration de ressources non nécessaires à la compréhension de votre contenu comme :
- Certains Fichier JS ou CSS
- Certaines Images ou vidéos
En ce qui concerne le blocage d’une page web, voici ce qui nous est dit :
« N’utilisez pas le fichier robots.txt pour masquer votre page Web dans les résultats de la Recherche Google. En effet, si d’autres pages redirigent vers la vôtre avec un texte descriptif, celle-ci peut être indexée sans avoir à être explorée. Si vous voulez empêcher l’affichage de votre page dans les résultats de recherche, utilisez une autre méthode, telle que la protection par mot de passe ou une directive noindex. »
L’utilisation de l’outil de gestion de paramètres dans la Google Search Console
Cet outil, assez ancien, n’a pas été migré sur la nouvelle GSC comme l’outil de désaveu de liens, mais il reste accessible via la section « anciens outils et rapports » en cliquant sur « paramètres d’URL ».
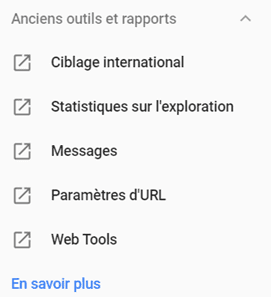
Il permet de lister dans la Search Console les divers paramètres de vos URLs et de les déclarer pour « bloquer l’exploration du contenu en double associé à des paramètres ».
Votre site web doit cependant respecter certaines conditions :
- Votre site compte plus de 1 000 pages ;
Dans vos journaux, vous pouvez voir que Googlebot indexe un nombre important de pages en double, dont la seule différence réside dans les paramètres d’URL
(par exemple : example.com?product=green_dress et example.com?type=dress&color=green).Exemple : j’utilise un moteur de recherche interne qui génère des URLs avec le paramètre « / ?search= »
Je le déclare dans l’outil et je peux sélectionner différentes options :
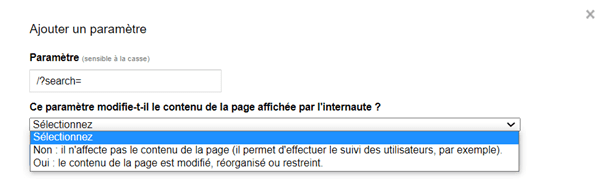
Utiliser cet outil permet de donner des informations en plus à Google, mais cela ne l’empêchera pas de visiter vos URLs et de les indexer.
Rien ne dit que l’outil sera encore maintenu bien longtemps, et nous savons que cela ne fonctionne pas. Du moins, vous ne pouvez pas uniquement compter sur cet outil pour gérer vos paramètres ou vos facettes.
Au même titre que le robots.txt, si Google estime qu’il y a un intérêt à ce que vos URLs à paramètres soient crawlées et visitées, il le fera.
L’exemple ci-dessous (cas client anonymisé) montre un paramètre renseigné dans l’outil paramètre d’URL de la Search Console pour « en bloquer l’exploration ».
Le paramètre « ?isPaginationRequest » est bien renseigné dans l’outil en « n’affecte pas le contenu de la page »
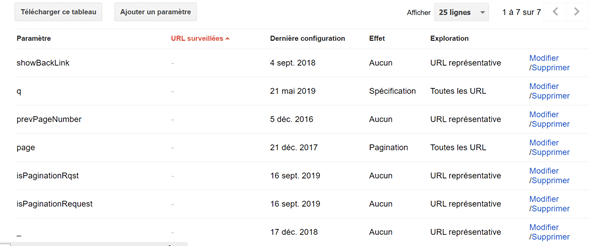
Or, l’analyse de logs menée montre non seulement que les pages contenant le paramètre sont crawlées et visitées par Google et que dans certains cas, l’URL avec paramètre est plus intéressante pour Google, car plus visitée et crawlée que l’URL sans paramètre.
| URL | Visits : Count On Period By Google | Crawls : Count On Period By Google |
|---|---|---|
| https://www.monsite.fr/frx/Catégorie/nom-de-la-categorie/nom-de-la-sous-categorie/nom-du-produit/marque/ref1235?isPaginationRequest=true | 59 | 18 |
| https://www.monsite.fr/frx/Catégorie/nom-de-la-categorie/nom-de-la-sous-categorie/nom-du-produit/marque/ref1235 | 5 | 5 |
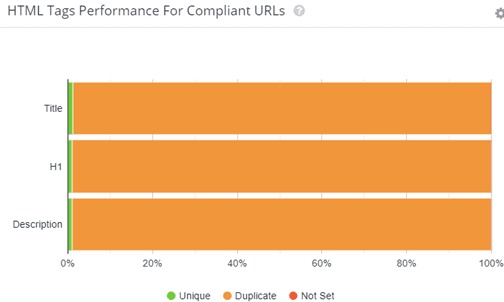
Ce problème, cumulé à d’autres, comme des facettes HTML accessibles au crawl nous donne un site avec un nombre d’URLs très élevé et une duplication de contenu importante :
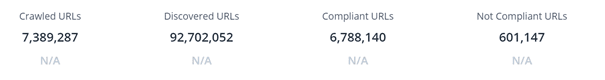
Eviter un Spider Trap : les vraies bonnes idées
Dans le cas où vous allez lancer un nouveau site avec des filtres et des facettes, nous vous conseillons les deux méthodes décrites ci-dessous : la technologie JS / Ajax, ou la méthode POST.
Utiliser la technologie JS / Ajax
Les facettes seront uniquement accessibles pour les utilisateurs et ne sont pas présentes dans le code source de la page et donc inaccessible aux robots.
Pour une implémentation idéale, nous vous conseillons de le faire côté client, c’est-à-dire côté navigateur et non coté serveur, car nous savons que Google exécute le JavaScript.
Utiliser la méthode PRG (Post-Redirect-Get) :
À l’inverse de la méthode GET, la méthode POST ne permet pas l’exécution des informations contenues dans un formulaire.
Un utilisateur clique sur un filtre d’une facette que vous ne voulez pas voir indexer, exemple : « voiture + coupé cabriolet 1996-2000 ». La requête serveur est envoyée en POST (pas d’exécution par Google).
Ensuite le serveur répond par une redirection vers l’URL filtrée et enfin, la redirection est suivie et renvoyée en GET pour que l’utilisateur puisse voir le résultat des filtres sélectionnés.
Elles doivent aussi être utilisées lorsque vous voulez corriger un spider trap existant, mais vous devrez dans suivre le processus expliqué plus bas.
Conseil de l’expert :
Le conseil que nous pouvons vous donner pour une bonne gestion des facettes est simple : il faut les rendre inexécutables pour les robots !
Rien ne vous empêchera par la suite d’ouvrir certaines facettes à l’indexation si elles ont un potentiel en étant associées à des requêtes SEO pertinentes pour votre activité.
Appliquez l’une des deux méthodes présentées et réellement fiables pour bloquer le crawl et l’indexation des facettes et ainsi éviter un spider trap et vous serez sauvé !
Comment corriger un Spider Trap actif ?
Si un spider trap est actif sur votre site et que, malheureusement, des milliers de pages dupliquées et ou non qualitatives sont indexées, voici les grandes étapes à suivre :
1. Identifier d’où vient le problème.
En réalisant un crawl, vous pouvez identifier les URLs parasites et essayer de comprendre comment elles sont générées.
S’agissant des facettes, il faut vérifier si elles sont exécutables par les robots (lien en HTML). Essayez alors d’en faire une liste exhaustive, ou à défaut d’identifier des patterns qui vont permettre de les identifier.
2. Opérer un nettoyage via la désindexation
Une fois les URLs listées, il faudra les désindexer en y ajoutant une balise noindex dans l’en-tête http. Bien vérifier que les pages que vous voulez voir retirer de l’index de Google ne sont pas bloquées dans le robots.txt via une commande Disallow. SI elles sont bloquées, ajoutez d’abord la noindex, puis ouvrez les pages via la commande Allow: pour que vos noindex soient découvertes par les robots.
Vous pouvez aussi créer un sitemap dédié que vous pousserez via le robots.txt.
Attention, ce processus est très long. Cela peut prendre plusieurs mois et vos performances SEO peuvent chuter, en particulier si vous avez des positions sur des URLs de facettes, mais ce n’est pas toujours le cas.
3. Fermez définitivement vos facettes
Faites évoluer la technologie de votre site web en choisissant entre les deux méthodes décrites plus haut : le JS / Ajax ou la méthode PRG (Post-Redirect-Get).
Vous l’avez compris, un spider trap peut facilement être évité. Les clients les plus susceptibles d’avoir ce type de problème sont ceux qui utilisent un CMS maison. La plupart des CMS actuels préviennent ce genre de problème. Il est de toute façon impératif de faire toutes les vérifications nécessaires sur ce sujet si vous voulez, comme presque tous les sites e-commerce, utiliser des facettes pour l’affichage de vos produits. Utilisez la technologie et le cerveau de vos développeurs plutôt que des outils et des méthodes qui ne fonctionnent pas et peuvent à terme, réellement pénaliser votre SEO.


